Neurons and Networks
Contents
Neurons and Networks#
With the pre-requisite math established, we can now start considering the question: what actually is a ‘neural network’ anyway? If you’re reading this page, there’s a good chance you’ve seen a diagram that looks something like this:
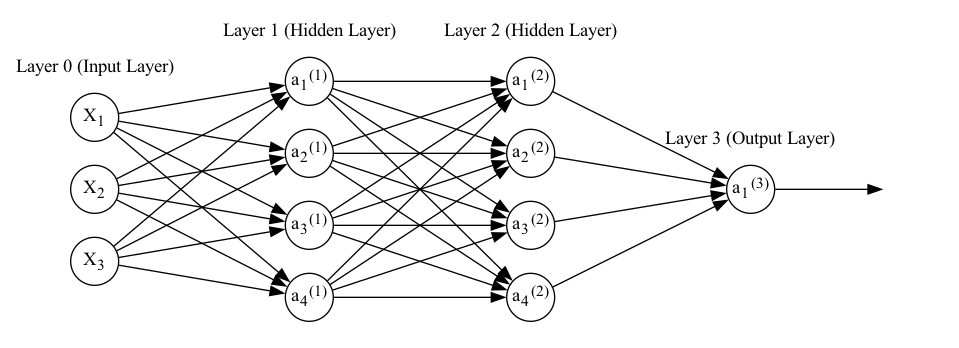
Fig. 1 A neural network with three inputs, two hidden layers with four nodes each, and a single output node#
But what is this diagram actually showing us?
A Single Neuron#
Before considering a whole neural network, it’s worth looking at a single node in the network. Looking at the above plot, a neuron is simply a single node in the hidden or output layers in the plot (more on these later). In particular, we’re going to consider the first neuron from the first hidden layer:
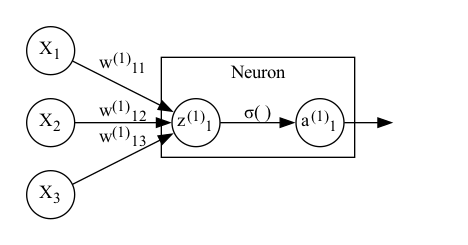
Fig. 2 A single neuron with three inputs#
For simplicity, we’ll consider what happens to a single training example (observation) with features (variables) \(\boldsymbol{X} = [X_1, X_2, X_3]\) and output \(Y\).
The first thing to notice is that here we’ve split the neuron into two, whereas in the first diagram neurons were comprised of a single node. This representation is somewhat more accurate to what’s going on, but the first diagram is useful for showing things at a higher level.
In this node#
To break this down step-by-step, \(X_1\), \(X_2\), and \(X_3\) are scalars that go in, something happens and we get \(z_1^{(1)}\). Then, this is passed on to \(\sigma()\), \(a_1^{(1)}\) is a scalar output, and this output is the output of the node..
Let’s start at ‘something happens’ Each of the inputs to the node is mupltiplied by a weight: \(w_{11}^{(1)}\) for \(X_1\), \(w_{12}^{(1)}\) for \(X_2\), and \(w_{13}^{(1)}\) for \(X_3\). The results of these multiplications are then summed to make \(z^{(1)}_1\).
Generalising to all nodes in a layer#
A general formulation of this is \(w^{(l)}_{ji}\). Here, the subscript I’m using for each \(w\) denotes the input node (\(i\), second number) and output node (\(j\), first number). The superscript \((l)\) denotes which layer the weight belongs to. The sum can be expressed as:
Note
I’m not bothering to index this by training example (althought strictly speaking we should) largely for the sake of simplicitly. Note that this will be true in some other equations on this page too. In general, individual elements such as \(z^{(l)}_j\), \(a^{(l)}_j\), and \(x_k\) exist per training example and would be indexed by this if I was marginally less lazy as a person.
This sum of multiplications is of course a dot product. We can therefore use matrix notation to organise all of the summed multiplications we need to do. This allows us to represent all of the equations for neurons and training examples in the input layer in a single, concise formula:
Note
A quick note for people used to social scientific notational conventions: \(\boldsymbol{X}\) has been transposed such that it is a column vector where each element is a feature (or variable, in statistical parlance). If it became a matrix, each row would be a feature and each column a training example (observation).
This is different from a more typical representation found in statistics, but is at least semi-common in the deep learning world. I use this format here due to the fact this is the most common format in the documents I have learned from, but it’s worth noting as this is not necessarily usual. More on dimensions below.
\(\boldsymbol{X}\) won’t always be presented with the \('\) symbol in all documents, but I’ve kept it on this page just to make this clear as it is fairly unusual.
Biases#
We also usually add a bias (intercept) \(b^{(l)}_{j}\) (i.e. intercept) to this equation for each node:
Which in matrix form for all nodes and observations becomes (note the use of broadcasting here):
Activation#
To get \(a_1^{(1)}\) from \(z_1^{(1)}\), we apply an activation function \(f(x)\). Don’t worry too much about the choice of function for now: there are many valid choices. The important think to note is that this function will take the weighted input \(Z\), and transform it in some way:
The neuron then provides \(a_1^{(1)}\) as its output.
We can generalise this as:
Networks are Composed Functions#
So: a neural network takes several input features (or variables, if you prefer). It multiplies that input by a matrix of weights, passes the results through an element-wise activation function, then repeats that process for each layer until it produces an output.
The output activation function will usually be chosen based on the nature of the output(s) - more on this later.
Temporarily and for simplicity, let’s imagine that \(f(x)\) and \(g(x)\) combine the multiplication and activation steps:
It’s easy to see that a neural network as described so far is really just a series of composed functions. For example, for the network diagram above:
Calculating the full output in this way is caled a forward pass or forward propagation.
It’s worth noting that the kind of network described here is a feedforward neural network. This is because we pass all the nodes from one layer to the next layer. Different network architectures may pass the nodes on in different ways. Recurrent neural networks for instance have layers take inputs from nodes further up the network.
Hopefully, this also makes the reason for a lot of the prequisites clear. We want to estimate this network as a function of its error (more on specific choices of error function later). This error is a function of the weights \(\boldsymbol{W}^{(l)}\) and biases \(\boldsymbol{b}^{(l)}\).
Gradient descent is a good option for finding the minimum of a function (and we want to find the minimum of the error function). So we need to find the derivatives of the error function for the network with respect to \(\boldsymbol{W}^{(l)}\) and \(\boldsymbol{b}^{(l)}\). And for that we need vector calculus and the chain rule.